

With the recent developments of Artificial Intelligence, there are many complex algorithms that exists. An algorithm is a set of instructions that are followed to achieve a common end goal by a computer program.
There are a lot of algorithms that were created for various reasons. With the rapid advancements of AI,, the most recent development is Deep learning algorithms with Neural Network architecture.
YOLO is a specific algorithm that is used for mainly as a subset of computer vision.
Artificial Intelligence:
Artificial intelligence is the major aera of development during recent years. There are numerous amounts of companies that invest in enhancing the full potential of AI. AI technologies also spreading across almost every industry including military, medicine, surveillance etc. AI has manty subfields including machine learning, deep learning, neural networks, etc. Artificial Intelligence is driven by distinct objectives that steer its advancement. The primary goals include: Enhanced Efficiency and Automation: Accelerate task completion and liberate individuals from monotonous duties. Improved Decision-Making: Leverage data to facilitate informed decisions, applicable to both corporate and personal contexts.
Computer Vision:
Computer vision is one of the major subfields in AI development. Just like the name itself, the main purpose of Computer vision is to give computers the ability to understand their surroundings and physical world on their own computational power (without human intervention) by analyzing visual data (images, videos) and a decision-making process (algorithms).
Computer is the major sub field of AI that use visual input data for self-decision making.
Computer vision is a subfield of AI.
Object detection:
Object Detection is a major part of Computer vision that is using neural network architecture (Deep Learning) to localize and classify objects in images, videos or live feeds (real-time). This is mainly used for recognizing objects. It deals with localizing a region of interest within an image and classifying this region like a typical image classifier. One image can include several regions of interest pointing to different objects. This makes object detection a more advanced problem of image classification.
Image localization is the process of identifying the correct location of one or multiple objects using bounding boxes, which correspond to rectangular shapes around the objects. This process is sometimes confused with image classification or image recognition, which aims to predict the class of an image or an object within an image into one of the categories or classes.
You Only Look Once:
You Only Look Once; commonly known as YOLO is popular algorithm that is widely being used for object detection purposes. it is popular due to its accuracy and speed than other object detection models.
The first version of introduced in 2016 by Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi in their famous research paper You Only Look Once: Unified, Real-Time Object Detection.
In their paper, they concluded that they said that the detection problem as a regression rather than a classification task by spatially separating bounding boxes and associating probabilities to each detected image using a single convolutional neural network.
Compered to other object detection algorithm models, YOLO has achieved state-of-art performance due to its accuracy and speed and beating the others by a great margin.
While advanced Neural Networks are using multiple layer architecture possible regions of interest using the Region Proposal Network and then performing recognition on those regions separately, YOLO just use one single-fully connected layer. Methods that use Region Proposal Networks perform multiple iterations for the same image, while YOLO gets away with a single iteration.
Several new versions of the same model have been proposed since the initial release of YOLO in 2015, each building on and improving its predecessor. Here’s a timeline showcasing YOLO’s development in recent years.
How YOLO works:
First the algorithms is being fed by visual input data (images, videos). Then this data will be sent through a Convolutional neural network to detect objects in the visual input data.
The first 20 convolution layers of the model are pre-trained using ImageNet by plugging in a temporary average pooling and fully connected layer. Then, this pre-trained model is converted to perform detection since previous research showcased that adding convolution and connected layers to a pre-trained network improves performance. YOLO’s final fully connected layer predicts both class probabilities and bounding box coordinates.
” YOLO divides an input image into an S × S grid. If the center of an object falls into a grid cell, that grid cell is responsible for detecting that object. Each grid cell predicts B bounding boxes and confidence scores for those boxes. These confidence scores reflect how confident the model is that the box contains an object and how accurate it thinks the predicted box is.
YOLO predicts multiple bounding boxes per grid cell. At training time, we only want one bounding box predictor to be responsible for each object. YOLO assigns one predictor to be “responsible” for predicting an object based on which prediction has the highest current IOU with the ground truth. This leads to specialization between the bounding box predictors. Each predictor gets better at forecasting certain sizes, aspect ratios, or classes of objects, improving the overall recall score. “
Source: v7Labs
There are several reasons for making YOLO more popular than other models for object detection purposes.
Speed:
YOLO is remarkably efficient due to its avoidance of complex pipelines, allowing it to process images at a rate of 45 Frames Per Second (FPS). Furthermore, YOLO achieves more than double the mean Average Precision (mAP) compared to other real-time systems, positioning it as an excellent choice for real-time processing. following figure shows the speed of YOLO compared to other major detection models.
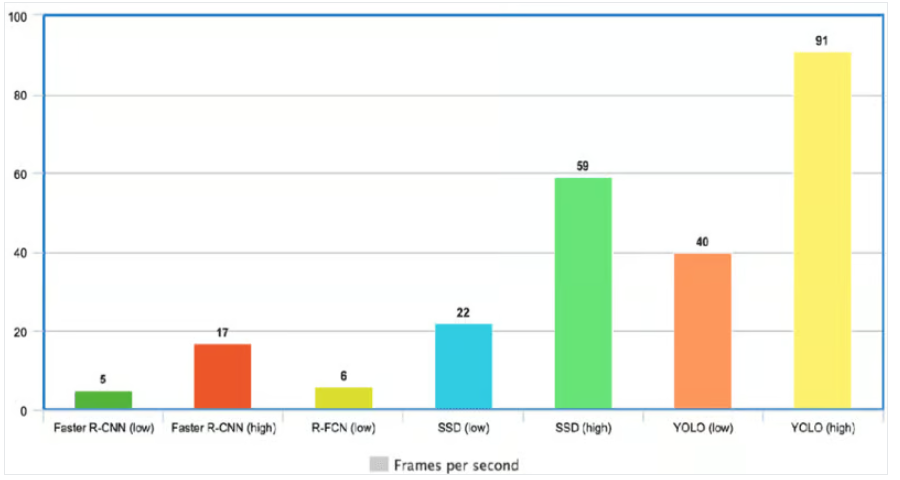
High-Accuracy:
YOLO is considered as the state-of-art performance in detection accuracy.
Generalization:
This is particularly applicable to the latest versions of YOLO, which will be elaborated upon later in the article. With these advancements, YOLO has further enhanced its capabilities by offering improved generalization for new domains, making it highly suitable for applications that depend on rapid and reliable object detection.
Open-source:
The decision to make YOLO open-source has enabled the community to continually enhance the model. This is one of the key factors contributing to the rapid advancements in YOLO within a short timeframe.
The following figure is the original YOLO architecture for introduced in 2016.

This is actually very similar to Google Net architecture. It has 24 convolutional layers, four max-pooling layers, and two fully connected layers.
The work process of architecture is described below.
- Resizes the input image into 448×448 before going through the convolutional network.
- A 1×1 convolution is first applied to reduce the number of channels, followed by a 3×3 convolution to generate a cuboidal output.
- The activation function under the hood is ReLU, except for the final layer, which uses a linear activation function.
- Some additional techniques, such as batch normalization and dropout, regularize the model and prevent it from overfitting.
Object detection with YOLO:

To understand the object detection process we are building a simple detection program YOLO.
for building a YOLO-based detection model, there are some some requirements that are needed to complete:
- IDE – development environment
- python installed
There are python-based libraries that are needed to be installed.
pip install opencv-contrib-python
pip install ultralytics
pip install numpy
pip install matplotlibNOTE: When you install the ‘opencv’, make sure the version is 4.9.
We need a weights file as the pretrained model for data analyzing. For this sample program, we are using yoloV8 (version 8).
download the file ‘yolov8m.pt’ from: GitHub
Then open the IDE and create a new python file. name the file as ‘detector.py’.\
Now , the first thing is to import all the necessary libraries. include the following code.
from ultralytics import YOLO
import cv2
import matplotlib.pyplot as plt
import numpy as npThen we must load the yolo pre-trained model from file path. for that:
# Load the YOLOv8 model (Pretrained on COCO dataset)
model = YOLO("enter the file path") # Use yolov8s.pt, yolov8m.pt, or yolov8x.pt for different versions
Then we must include the path for input images folder import them from the folder for detection.
# Load an image
image_path = "./input/input_img1.jpg" # Replace with your image path
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # Convert BGR to RGB for displayThen we must initialize the the detection process to get the precious results. for that we writing following code:
# Perform Object Detection
results = model(image)
# Show the results
results[0].show() # Display the image with detections
# Optionally save the image with detections
results[0].save("output.jpg")
Finally, we must extract results of the detection process as the output after the detection.
# Extract results
for result in results:
for box in result.boxes:
x1, y1, x2, y2 = map(int, box.xyxy[0]) # Bounding box coordinates
confidence = float(box.conf[0]) # Confidence score
class_id = int(box.cls[0]) # Class ID
label = model.names[class_id] # Get class label
# Draw bounding box
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(image, f"{label}: {confidence:.2f}", (x1, y1 - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
Since, the program is complete, now we add the code for showing the final output result of detection and saved final output image separately.
# Display image with bounding boxes
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.axis("off")
plt.show()Now we can run the program. make sure you have included the directory for input images before run the program.
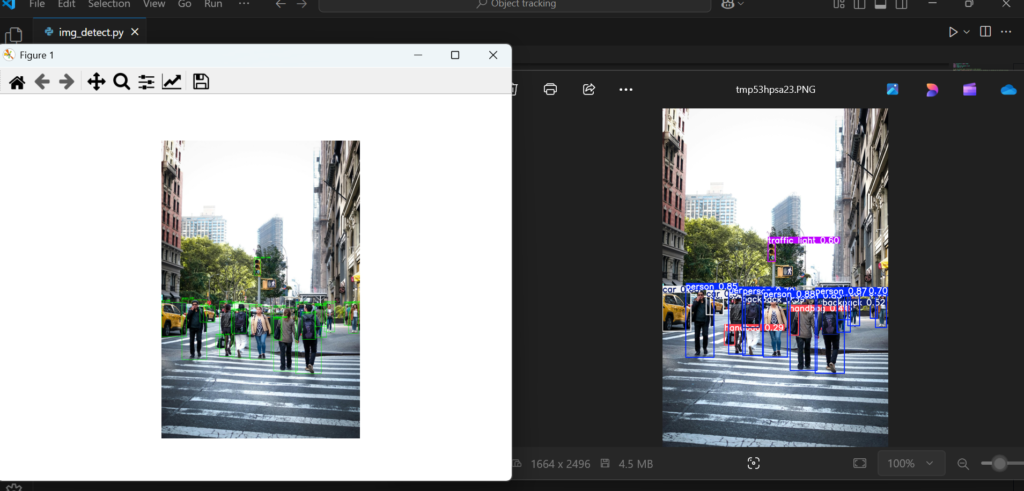
The final output will look like this:
YOLO object detection process:
Yolo algorithm works on 4-initial approaches. They are:
Residual blocks:
During this process, the original image will be divided to cells/grids which are equal to each other.
Bounding Box regression:
The next step is to determine the bounding boxes corresponding to rectangles, highlighting all the objects in the image. We can have as many bounding boxes as there are objects within a given image.
YOLO determines the attributes of these bounding boxes using a single regression module in the following format, where Y is the final vector representation for each bounding box
Intersection Over Unions or IOU:
Most of the time, a single object in an image can have multiple grid box candidates for prediction, even though not all are relevant. The goal of the IOU (a value between 0 and 1) is to discard such grid boxes to only keep those that are relevant.
Non-Maximum Suppression:
Setting a threshold for the IOU is not always enough because an object can have multiple boxes with IOU beyond the threshold, and leaving all those boxes might include noise. Here is where we can use NMS to keep only the boxes with the highest probability detection score.
Finally, we must conclude the modern applications of object detection. There are several industries that use object detection as a major part of their daily operations including:
- Healthcare and medical
- Agriculture
- Security and Surveillance
- Self driving cars and autonomous vehicles
Object detection is becoming more and more advanced day by day due to rapid advancements of Artificial intelligence. So, YOLO also has upgraded to several over the years. There are 11 versions of YOLO at the moment. The final yolov11 was released on 2024. But most commonly used versions are yolov3, yolov5, yolov7 and yolov8.
This article looked into a brief overview of YOLO algorithm and how it works.